
- Openai has released GDPval, a new evaluation system to test how AI works on work -related tasks
- Claude Opus 4.1 comes out in the lead with ‘Chatgpt-5 High’ in second place
- Tasks include things like e -maile an answer to a dissatisfied customer
We are all familiar with AI -Benchmarks that measure performance in certain tasks, but often these tasks do not reflect the real world and how people actually use AI, especially at work.
To combat this problem, Openai, the manufacturer of Chatgpt, GDPval, introduces a new way of measuring AI model performance using the real world’s tasks compared to a real human being across 44 professions, from software developers and lawyers to registered nurses and mechanical engineers.
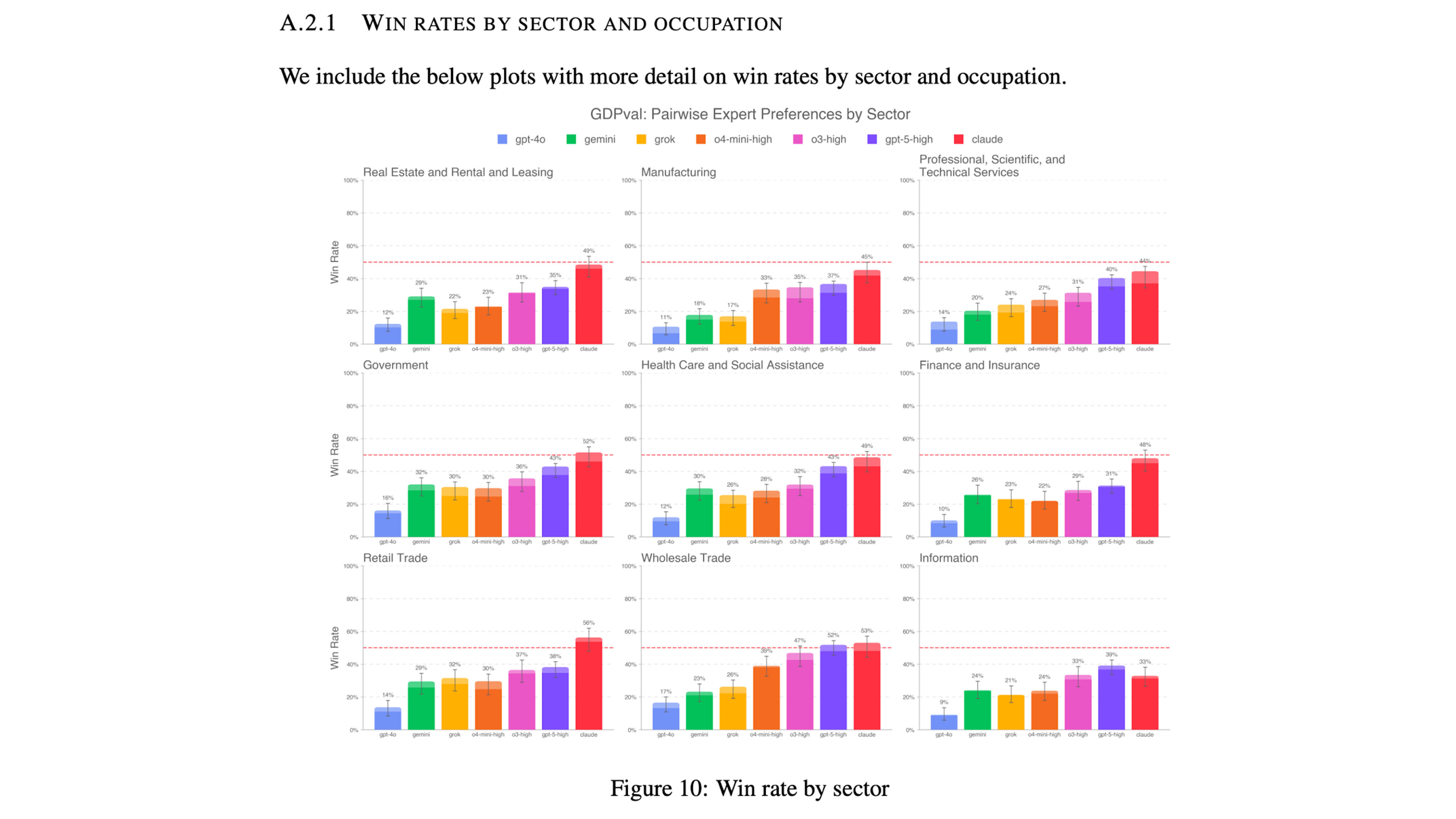
Surprisingly, the Openai study shows that the best functioning model was the Anthropic’s Claude Opus 4.1, which not only exceeded Openais GPT-5, but also Gemini and Grok.
Gdpval Win Rate
This graph shows the overall GDPval gain rate (the times when AI did better than an industry expert) and shows that Claude Opus 4.1 is at the forefront with a victory rate of 47.6, with ‘Chatgpt-5 High’ coming a second with 38.8 and ‘Chatgpt O3 High’ of 34.1. Chatgpt-4o scores the lowest, with a winning speed of 12.4, which is significantly behind Both Back 4 and Gemini 2.5 Pro.
The study found that Claude was the highest priest over eight of the nine industrial sectors, the tested, including government, health care and social assistance. The results clearly show that Claude Opus 4.1 leads over a wide range of work -related tasks.
Examples of the tasks include things such as e -maile to an answer to a dissatisfied customer who requests a return, optimizes a table layout for a spring supplier fair and audit price discrepancies in purchasing orders.
What’s in a name?
The name used by Openai, GDPval, comes from the concept of gross domestic product (GDP) as a key economic indicator. Openai wants GPDval to be adopted extensively to help grounding for future AI improvements in evidence rather than guesswork.
Releasing the results showing a competitor ahead seems to be an exercise in radical transparency of Openai, but it fits perfectly with the company’s philosophy. “Our mission is to ensure that artificial general intelligence benefits from all of humanity. As part of our mission, we want to transparently communicate progress on how AI models can help people in the real world,” reads a statement from Openai.
The paper, which can be read in its entirety online, comes a week after Openai released a more consumer-focused paper showing that the majority of chatgpt users (70%) actually used it at home, rather than at work.
The study was conducted by Openai’s economic research team and Harvard Economist David Deming for the National Bureau of Economic Research (NBER). The results were surprising to many people, who in the past, the focus of new chatgpt releases have been very focused on work-related tasks such as coding, to keep presentations and be a good research tool.
The news that Claude Opus 4.1 is better at actual work-related tasks, not just benchmarks than even ‘chatgpt-5 high’ could mean a renewed focus from Openai against its changing user base.


