- Maker of the fastest AI -chip in the world makes a splash with deepseek onboarding
- Cerebras says the solution will rank 57x faster than on GPUs but don’t mention which GPUs
- Deepseek R1 is running on Cerebras Cloud and the data stays in the US
Cerebras has announced that it will support Deepseek in a non-so-surprising feature, more specifically the R1 70B reasoning model. The move comes after Groq and Microsoft confirmed that they would also bring the new child of the AI block to their respective clouds. AWS and Google Cloud have yet to do so, but anyone can run the Open Source model everywhere, even locally.
AI Inference Chip Specialist will run Deepseek R1 70B at 1,600 tokens/second as it claims is 57x faster than any R1 provider using GPUs; One can deduce that 28 tokens/second is what the GPU-in-the-Cloud solution (in this case Deepin from) apparently reaches. Serendipithed is Cerebra’s latest chip 57x larger than H100. I have reached Cerebras to find out more about this claim.
Research from Cerebras also demonstrated that Deepseek is more accurate than Openai models on a variety of tests. The model runs on cerebras hardware in US-based data centers to cushion the concerns about privacy that many experts have expressed. Deepseek – The app – sends your data (and metadata) to China where they are likely to be saved. Nothing surprising here like almost all apps – especially free – catches user data for legitimate reasons.
Cerebras Wafer Scale Solution positions it unique to take advantage of the impending AI -Sky -Inferens Boom. WSE-3, which is the fastest AI-chip (or HPC accelerator) in the world, has nearly a million kernels and a staggering four trillion transistors. More important, however, it has 44 GB of SRAM, which is the fastest memory available even faster than HBM found on NVIDIA GPUs. Since the WSE-3 is only a huge matrix, the available memory tape with huge, more ordering orders is larger than what the NVIDIA H100 (and for that matter H200) can muster.
A price war brewer in front of the WSE-4 launch
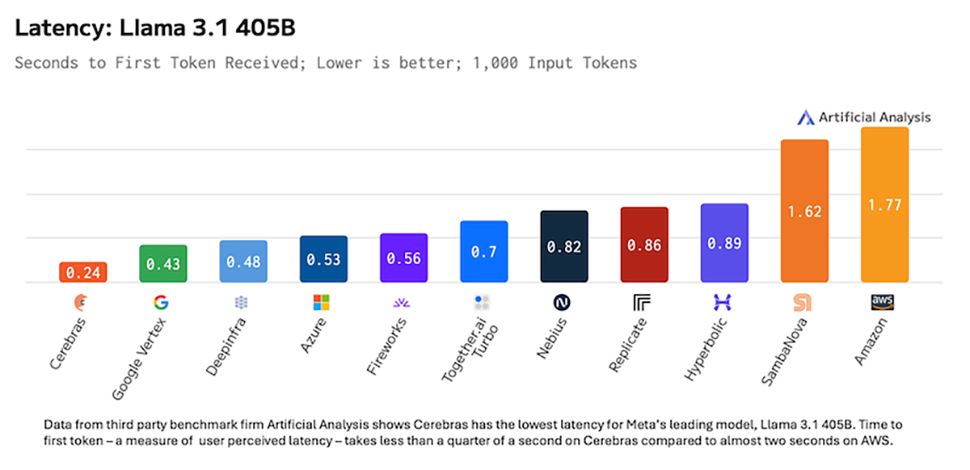
No pricing has been revealed yet, but Cerebras, which is usually about the special detail, revealed last year that Llama 3.1 405b at Cerebras -inferens would cost $ 6/million input -tokens and $ 12/million output -tokens. Expect Deepseek to be available for much less.
WSE-4 is the next iteration of WSE-3 and will deliver a significant boost in the performance of Deepseek and similar reasoning models when expected to be launched in 2026 or 2027 (depending on the market conditions).
The arrival of Deepseek is also likely to shake the proverbial AI money tree, bring more competition to established players like Openai or Anthropic and push prices down.
A quick look at DOCSBOT.AI LLM API pockets show that Openai is almost always the most expensive in all configurations, sometimes of several size orders.